CLUSTEREASY uses ``slab decomposition,'' meaning the grid is divided
along a single dimension (the first spatial dimension). For example,
in a 2D run with ![]() on two processors, each processor would cast a
on two processors, each processor would cast a
![]() grid for each field. At each processor the variable
n stores the local size of the grid in the first
dimension, so in this example each processor would store
grid for each field. At each processor the variable
n stores the local size of the grid in the first
dimension, so in this example each processor would store ![]() ,
,
![]() . Note that n is not always the same for all
processors, but it generally will be if the number of processors is a
factor of N.
. Note that n is not always the same for all
processors, but it generally will be if the number of processors is a
factor of N.
In practice, the grids are actually slightly larger than ![]() because
calculating spatial derivatives at a gridpoint requires knowing the
neighboring values, so each processor actually has two additional
columns for storing the values needed for these gradients. Continuing
the example from the previous paragraph, each processor would store a
because
calculating spatial derivatives at a gridpoint requires knowing the
neighboring values, so each processor actually has two additional
columns for storing the values needed for these gradients. Continuing
the example from the previous paragraph, each processor would store a
![]() grid for each field. Within this grid the values
grid for each field. Within this grid the values ![]() and
and
![]() would be used for storing ``buffer'' values, and the actual
evolution would be calculated in the range
would be used for storing ``buffer'' values, and the actual
evolution would be calculated in the range ![]() ,
, ![]() .
.
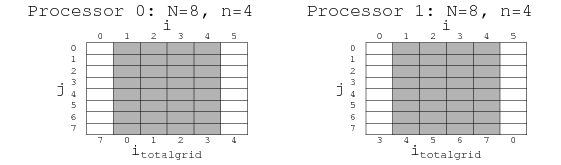
This scheme is shown above. At each time step each processor
advances the field values in the shaded region, using the buffers to
calculate spatial derivatives. Then the processors exchange edge
data. At the bottom of the figure I've labeled the ![]() value of each
column in the overall grid. During the exchange processor 0 would send
the new values at
value of each
column in the overall grid. During the exchange processor 0 would send
the new values at
![]() and
and
![]() to processor
1, which would send the values at
to processor
1, which would send the values at
![]() and
and
![]() to processor 0.
to processor 0.
The actual arrays allocated by the program are even larger than this,
however, because of the extra storage required by FFTW. When you
Fourier Transform the fields the Nyquist modes are stored in extra
positions in the last dimension, so the last dimension is ![]() instead of
instead of ![]() . The total size per field of the array at each
processor is thus typically
. The total size per field of the array at each
processor is thus typically ![]() in 1D,
in 1D,
![]() in 2D
and
in 2D
and
![]() in 3D. In 2D FFTW sometimes requires
extra storage for intermediate calculations as well, in which case the
array may be somewhat larger than this, but usually not much. This
does not occur in 3D.
in 3D. In 2D FFTW sometimes requires
extra storage for intermediate calculations as well, in which case the
array may be somewhat larger than this, but usually not much. This
does not occur in 3D.